Order which images are converted from 2-D grid into 1-D sequences of patches
- row-major
- column major
- Hilbert curves
- Spiral
- Diagonal
- Snake
Transformers as sequence models for vision. Self-Attention + Positional Embeddings =. Permutation-Equivariant. Inductive biases = locality, recurrence, input-dependent state dynamics Sparse Attention Plackett-Luce ranking model
- Image transformer → self attention on local neighborhoods of patches
- Vision Transformer (ViT) → global self-attention
- operation in computation and space
- not efficient
- Sparse Attention
- Longformer
- Transformer-XL
- Mamba & ARM
- Hierarchical tokenization
- process image at multiple scales to reduce sequence length at higher levels
- Specific order for sequence
Key Idea: Patch Order Sensitivity
- long context model forget stuff in NLP
- Use RL to rank patches permutation to find most effective
Preliminaries
- Permutation equivariance of full self-attention not desired for vision
- positional embeddings (Transformer-XL)
- absolute
- native relative
- positional embeddings (Transformer-XL)
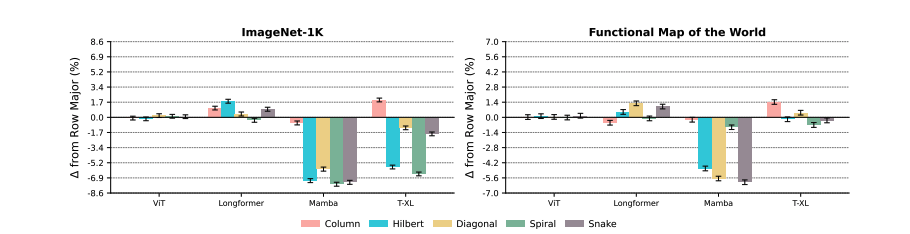
Does Patch Order Matter ?
Compression % reduction ?
- LZMA, identify repeating patterns and reusing earlier parts of the sequence encode later parts more efficiently ?
Learning an Optimal Patch Ordering with REOrder
optimal ordering for each model-dataset pair sequence compressibility vs downstream performance more similar content = more compressible = not as good ? sometimes
- discretize images using a VQ-VAE based model
- encode resulting token sequence codes using unigram and bigram tokenization
- measure compression ratio by LZMA
Q: what else is needed other than compression ratio ? Model specific ?
Learning to Order Patches
stochastic policy learning problem policy ⇒ distribution over permutations REINFORCE algorithm - Plackett-Luce policy (ordered decisions)
- salient patches are moved to the end of the sequence ? more relevant to identify
Longformer not really affected because it is already near full attention
Information-Theoretic Initialization
Reference To Follow Up
- Understanding and improving robustness of vision transformers through patch-based negative augmentation
Question
- generalizability of REOrder policy
- meta-learning
- REOrder for other task
- object detection
- segmentation ← def not likely
- captioning
- spatially sensitive tasks
- multi-label
- dense prediction
- visual reaosning
- Differentiable or more efficient ordering
- Replace REINFORCE with Gumbel-Sinkhorn, softsort, differentiable sorting
- Dynamic reordering at inference time
- adaptively reorder patches at inference time based on partial activations ?
- lightweight model that reorders its input patches based on intermediate saliency predictions
- can this be done efficiently, using early layers or auxiliary heads ?
- adaptively reorder patches at inference time based on partial activations ?
- Relationship between patch order and model inductive bias
- Self-supervision or contrastive or reconstruction loss
- DINO-style pretraining
- spatio-temporal transformers
- VideoMAE, CLIP
- Curriculum learning via patch ordering ?
- go in reverse from what the policy learn.
- faster training ?
- step size ?