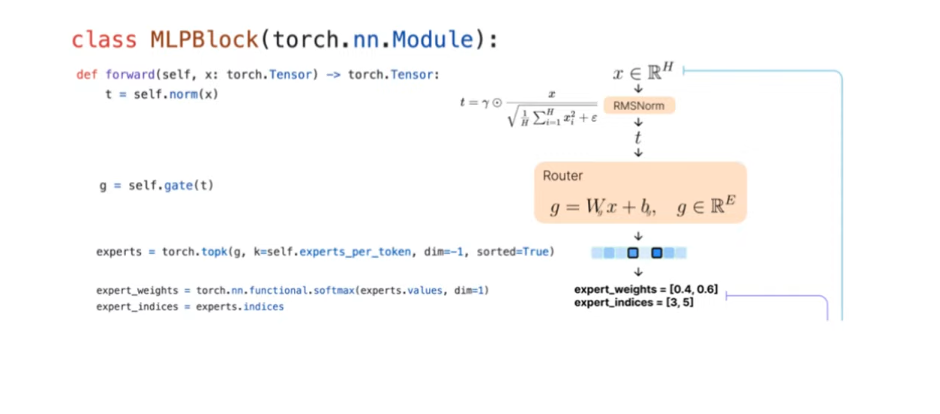
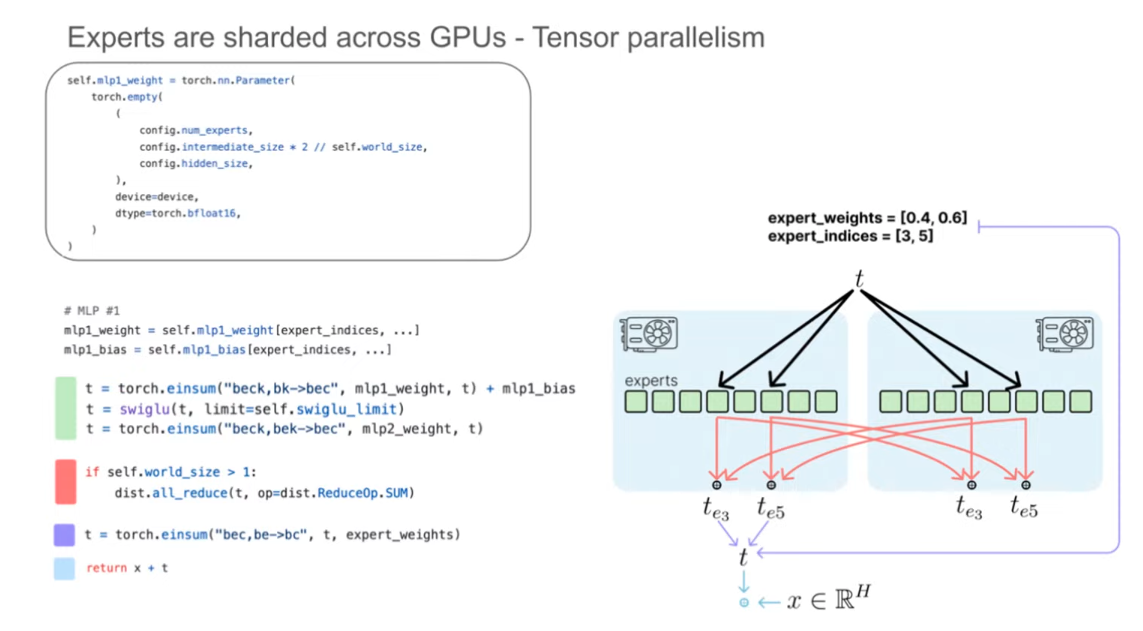
Main Idea
How to use MoE to enable training on distributed datasets owned by different parties
- starting model trained on public data
- set of local data
- recombine
Other Options
- Model Merging
- Model soup
- Ensembling
- MoE merging
- add router in front of feed forward network (with seperate FFN from each source)
- model soup for other layers (Norm, MHA, Norm)
- router needs to train on all data ← problem if ppl want their data to be private
Solutions
- Learning to Coordinate
- all distributed source trains two experts, one is frozen , second is being trained. everyone shares the same frozen expert.
- Nonparametric Router
- total router size when recombined = . Where is total number of experts.
- When training only use . One for the frozen part, one of the active expert.
- q: is there some kind of positional bias ?
Question/ Ideas
- How does the router know which expert to direct to ?
- What if two experts understand things differently ?
- Adding different modality ? Vision ? open research question Mixture of Transformers ?
- Original model to use from is already a mixture-of-expert so instead of freezing 1 expert when training a new one, freeze n-1 experts (the original model).
- Add a tiny model. Which expert to assimilate the tiny model to.
- A “tiny model” could in principle be aligned via the similarity mechanism (their scoring), but the quality of assimilation would depend on whether the tiny model’s embedding space can be aligned with the anchor’s residual stream
- how to make a benchmark ?
- Freeze the subject expert and do post-merger training for the public anchor model.
Open Problems
- Can we make use of fine-grained MoE to enable fine-grained data addition ?
- scaling # of experts ?
- Can we leverage this architecture & training to allow continual learning ?
- How to better train a nonparametric router ?
- Harmful expert ?
- Try using a bunch of tiny llm ? to try
- how to make a benchmark for tiny stuff ?
- use more experts but weighted ?
Routing Load Balancing How to allow people to contribute specialized experts continually?